More this week in my series on how GoldenSource collaborates with data vendors – this time, an overview of how our unified data model is being used to garner broader and deeper insights for the buy side and the sell side alike.
A unified data model is a bit of a paradox, in that it’s simultaneously focused on one specific view but at the same time also substantial enough to provide the range of insights you require to make meaningful investment decisions.
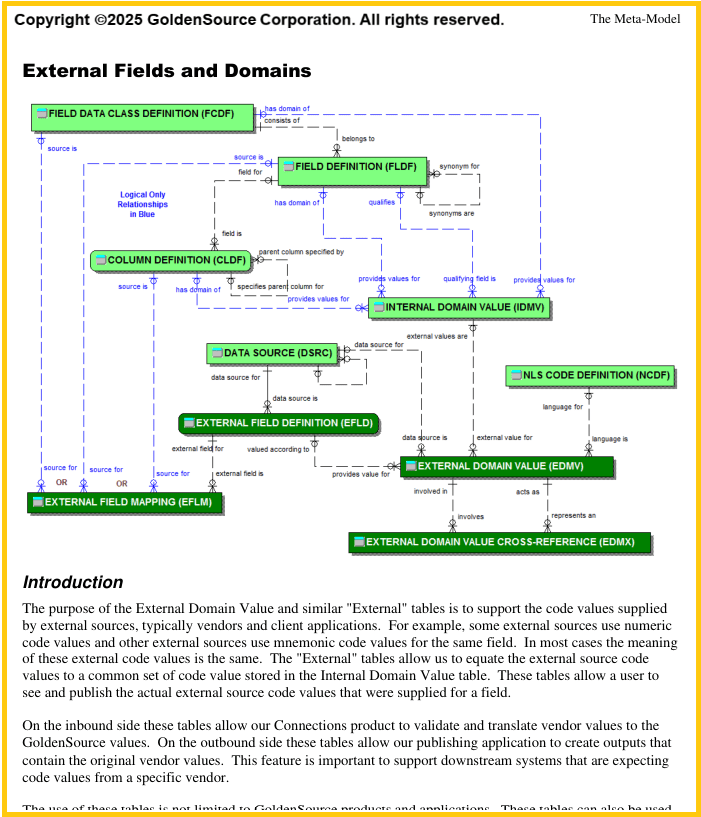
As I’ve mentioned previously, certain core functionalities in a data management solution must address multi-sourcing requirements. To support this, the solution depends on a data model designed to capture and represent information in a way that inherently supports multi-sourcing.
Our extensive experience in building and managing ‘Gold Copies’ has shown that several key capabilities are essential.
First, the solution must support the prioritization of data sources—from high-level preferences down to very granular configurations—by enabling the capture of source-level detail at the level of data groups or even individual attributes. Closely related to this is the concept of domain values. That is, each source may use a different value to represent the same concept, and the data model must recognize and accommodate this variation.
A robust solution must also be capable of creating a Gold Copy that retains the full lineage of each source’s contributed values. In some cases, even within a single master record, certain data domains must remain source-specific because of inherent differences in how data providers structure their content. This often starts with proprietary identifiers and extends to complex structures like corporate hierarchies, where no two providers present the same view.
In situations where merging into a single unified Gold Copy is either not possible or not desirable, the data model must instead support intelligent linkages between these different views. Take corporate hierarchies, for example. It’s a given that multiple views of the same organization will diverge. A well-designed data model, as well as the mastering application itself, must work with this reality through smart cross-referencing strategies.
Finally, while industry-standard classification schemes are typically supported, many data providers also use their own taxonomies. A multi-sourcing-savvy data model must not impose a single view but rather allow for the creation of a unified, possibly certified classification, or, in some cases, the deliberate use of multiple views when each has value in the context of downstream systems.
Next week, I’ll share some more thoughts on our unified data model and why it’s so important to retain all the individual contributing views to arrive at a single source of truth.