
Now that you know the benefits of a data lake house, how should you structure it? Our four-tiered lake house framework approaches this task with an extract-load-transform (ELT workflows) variation of the ETL method.

Think of a data lake initially as the raw data level of corporate data. Sitting atop raw data are structured, refined and aggregated levels where the data that is of more interest has been further processed. Let’s look at what is happening at each level:
- Raw: no data exceptions are generated, 100% of the data is accessible 100% of the time, this data is brought in without rules applied and in the source provider format.
- Structured: the first level of the process, which maps data into common domain and attribute ‘types’ and into a target business information model where applicable, allowing for further and more complex processing, cross comparison and extraction.
- Refined: first level of exceptions raised as rules are applied for data enrichment and data structure, mainly technical in nature.
- Aggregated: production ready data, the final data layer within the data-lake. At this stage the most complex data transformations take place with concepts such as hierarchies, aggregation, additional data linkages to ‘gold copy’ data versions, additional business rules transforming the data into an operational data master.
Target data lake house design
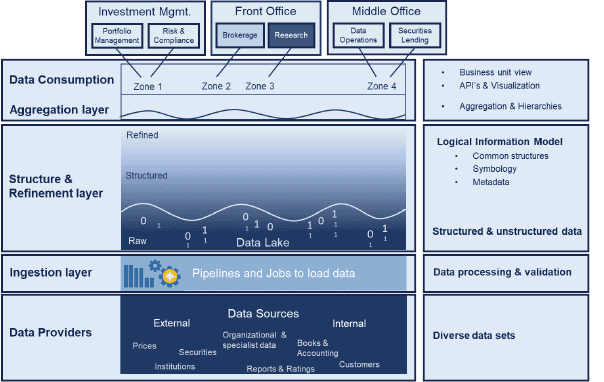
To give you an idea of how the data volumes narrow at each level, a global European-based bank has an initial data lake of 36 million financial instruments at the raw data level. The instruments it trades most, which require technical exceptions to be addressed, amount to about 400,000 at the refined level. At the aggregated level for this bank, the number of instruments narrows to about 10,000, for which functional exceptions must be addressed.
The value of ELT Workflows
ELT workflows make it possible to build the data lake house by filtering and processing data at the structured, refined and aggregated levels. ETL, its predecessor, operates like a “big bang,” performing all the technical and business operations (akin to functional) exceptions on all the data, in one shot, in advance of data being made available to the business, and preventing availability until exceptions are resolved. Although more nimble and flexible, ELT workflows don’t offer the same precision as ETL, however.
Data lake house ELT workflows
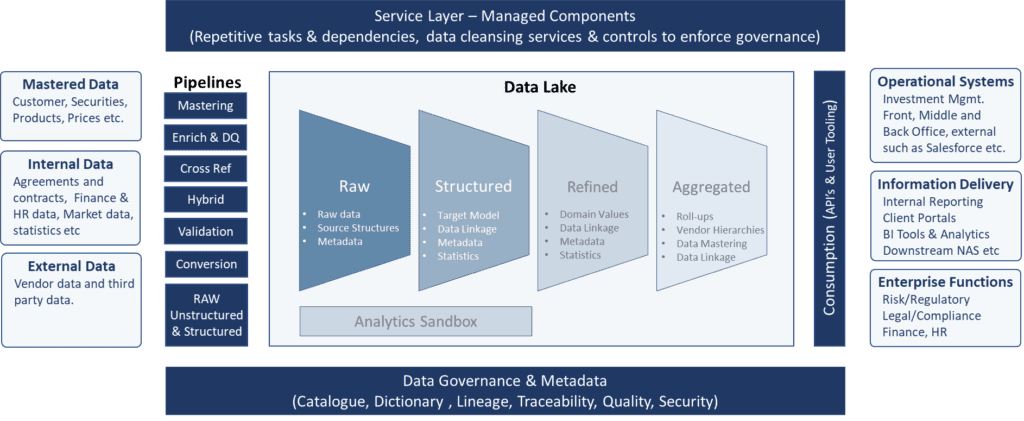
Using ELT workflows, as the more advanced levels do, actually creates fewer exceptions with data, because it only kicks out the data that really would cause issues for your institution. It narrows down the exceptions to the most difficult business issues at these top levels. For instance, simple data such as transaction data (i.e. time stamps on transactions) would be handled at the structured level, because it does not need scrubbing, it would be transformed to a common format directly into refined or aggregated (no rules applied). Ratings agency data, where there are differences in the ratings that different agencies have given a financial instrument, would go to the aggregated level, to process those exceptions.
What is the difference between ELT and ETL?
The difference between ELT and ETL is that the workflow moves the transform step later, which means that ELT moves the data along quicker. Having raw, structured, refined and aggregated levels means the data that doesn’t need more scrutiny gets moved along and out of the way, instead of bogging down a data lake house by treating all of it with the same scrutiny at the outset.
A cloud data warehousing service like Snowflake receives operational data that belongs at our raw or structured data levels, fed by major data sources such as Bloomberg, S&P, Morningstar and Moody’s. So this four-tier data lake house design handles the data processing more efficiently and accurately, without major firms having to build their own data engines. Key to this is the data lake house data schema, which natively enables the ELT workflows methodology to function smoothly in an operational environment.
While data lakes have brought data processing further along, you’ll find that data lake houses with more sophisticated capabilities for data organization and processing are what will advance data management as a discipline in the future. Data lake houses get to the core of what firms need to address in their data.