
In a previous Point by Point article, titled A Taxonomy for Data Analytics in Financial Services, we presented a hierarchical classification of typical analytics across buy side and sell side firms. In order to execute these analytics, an analytics architecture is needed, which are systems and/or tools, such as quant libraries, that support the data and process flows.
A typical analytics architecture in financial services must cover five categories:
- Market Data Analytics
- Business Reporting
- Quant Research & Development
- Investment Analytics
- Econometric Analysis

Core Components of Analytical Data Architecture
The core components of analytical data architecture ensure not only that the right data available and accessible for each type of analytic, but also that data governance is embedded throughout the analytics activities of the business.
The diagram below describes an analytics architecture that supports all five categories listed above.
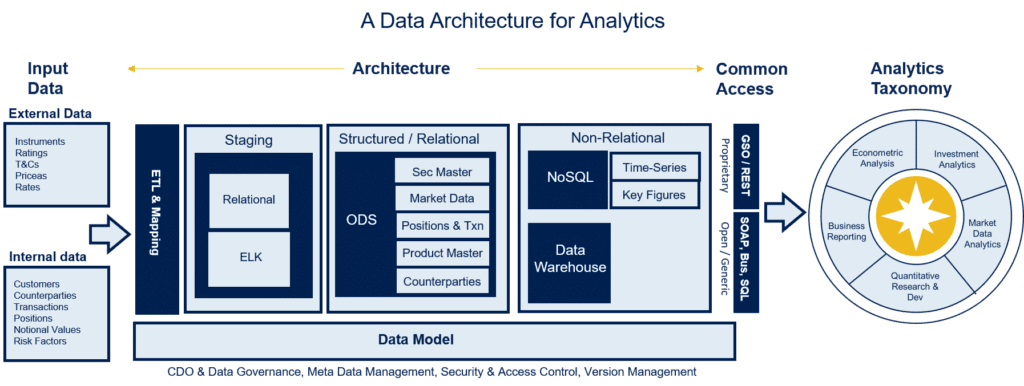
- Internal versus External Data
- internal data is specific to the firm’s positions, trades, risks, valuations and P&L
- external data is information relating to instruments and prices that is available typically via vendor feeds
- ETL and Mapping
- ETL stands for Extract, Transform and Load. The purposes of this layer is to take data from various internal and external sources then map it and normalize it
- The Mapping tool needs to be able to map source data attributes to attributes in the target data model
- Staging
- The Staging layer stores the raw input data. It can be important to have the raw data stored in a staging layer so that it can be referenced for audit and data lineage purposes after it has been normalized
- Structured / Relational data store
- Stores normalized attributes along multiple data dimensions. The key dimensions are
- Instrument
- Book
- Portfolio
- Trading Desk
- Product
- Counterparty
- For each data dimension, the structured data model contains
- normalized attributes
- unique identifiers
- related attributes (both normalized and source)
- Non-Relational
- The Data Warehouse supports
- both normalized and de-normalized attributes
- as-reporting
- bi-temporal reporting
- aggregation of numeric values along key dimensions
- The NoSQL store supports
- flexible schemas for the storage and retrieval of data beyond the traditional table structures found in relational databases
- storage and management of data in ways that allow for high operational speed and great flexibility on the part of the developers
- time-series and statistical calculations and analysis
- Common Access Layer
- A common access layer is required to access and join data that resides in the Staging, Relational and Non-Relational stores
- This is commonly a proprietary object layer that creates numerous business-focused abstractions of the data and makes them available to users for ease of allowing for a common view of data across the different types of underlying data stores
- The Data Warehouse supports
- Stores normalized attributes along multiple data dimensions. The key dimensions are